

【競プロの基本】Pythonで幅優先探索を実装してみる

はじめに
こんにちは、NRIデジタルでデータサイエンティストをしている鈴木実奈と申します。
NRIデジタル内には「初めての競プロサークル」という有志活動があり、私もその中で日々楽しく競技プログラミングについて学んでいます。
プログラミングを用いて与えられた問題を解くスピードを競う競技プログラミングにおいて、効率的に計算・処理が行えるアルゴリズムを学ぶことは重要です。
そのため、「初めての競プロサークル」では過去のコンテスト内容・解法の共有や典型問題対策勉強会といった活動を行っています。
今回は競技プログラミングの典型問題に用いられる著名なアルゴリズムの一つである「幅優先探索」についてご紹介します。
幅優先探索とは
幅優先探索は、「A駅からB駅に行くときに複数の経路が考えられる場合、最短な経路はどれかを知りたい」などの事例に用いることができます。
競技プログラミング的に説明すると、
グラフや木構造を探索するためのアルゴリズムの一つで、
始点となるノード(*)から隣接するノードを探索し、そこからさらに隣接するノードにたいして探索を繰り返す
というものです。
*ノード:グラフの頂点のこと。頂点同士を結ぶ辺は「エッジ」という
言葉では分かりづらいので、以下の図を見てみましょう。
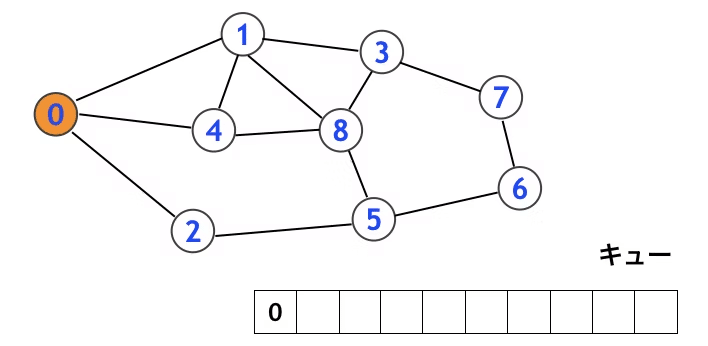
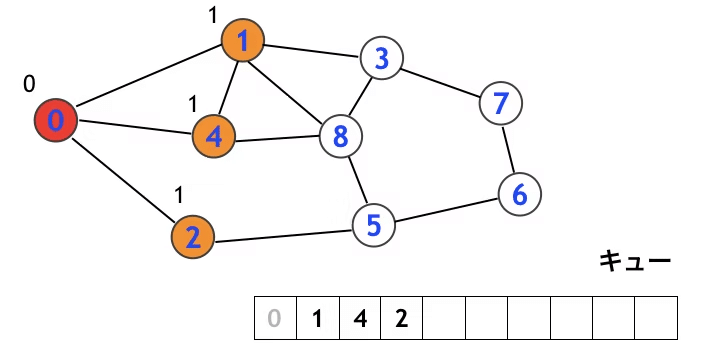
まずはこの3つをキューに入れ「既に訪問済み」のしるしとします。
このとき、ノード0からノード1, 4, 2までの距離はすべて1とします。

まだ訪問していないノード3, 8, 5をキューに追加します。
これらのノード0からの距離は2となります。
このように、グラフ上のノードに対して「出発地点から近い順に」探索するのが幅優先探索の流れです。
対となるアルゴリズムに「深さ優先探索」というものもあります。
幅優先探索が「出発地点から近い順」とすると、深さ優先探索は「出発地点から行けるところがなくなるまでとりあえず進む」ような手法です。
参考:https://qiita.com/drken/items/4a7869c5e304883f539b
問題設定
今回は、上記のようなグラフに対して、「すべてのノードに対する出発地点からの最短距離」を求めることとします。
具体的には以下のような入出力になるようなアルゴリズムを実装します。
想定される入力
1行目にノードの数(n個)、エッジの数(m本)
2行目以降はエッジがどのノードとどのノードをつなげているか
が入力されるとしましょう。
例えばノード4個でエッジ5本、つながっているノードが(1, 2)、(1, 3)、(2, 3)、(3, 4)、(4, 2)なら
4 5
1 2
1 3
2 3
3 4
4 2という入力になります。
想定される出力
幅優先探索を用いてノード1からすべてのノードの距離を出力したいです。第 i 行にノード1からノード i までの最短距離を出力する、ということにしましょう。
例えば上記の「想定される入力」に対しては
0
1
1
2という出力が期待されます。
ノード1からノード1の距離は0と定義したので1行目は必ず0になります。
また、例えばこの出力の4行目は2となっていますが、これは「ノード1からノード4の最短距離は2」という意味になります。
実装
上記の入出力を満たす実装が以下になります。
ここからは実装の中身について解説していきます。
from collections import deque
n, m = map(int, input().split()) # 1. ノード・エッジ数の受け取り
graph = [[] for _ in range(n+1)] # 2. グラフ作成
for i in range(m): # 3. エッジの受け取り・グラフへの反映
a, b = map(int, input().split())
graph[a].append(b)
graph[b].append(a)
dist = [-1] * (n+1) # 4. 最短距離リストの作成
dist[0] = 0
dist[1] = 0
d = deque() # 5. 訪問ノードを格納するキュー(deque)の作成
d.append(1)
while d: # 6. 幅優先探索
v = d.popleft()
for i in graph[v]:
if dist[i] != -1:
continue
dist[i] = dist[v] + 1
d.append(i)
ans = dist[1:] # 7. 最短距離の出力
print(*ans, sep="\n")1. ノード・エッジ数の受け取り
n, m = map(int, input().split()) # 1. ノード・エッジ数の受け取り入力1行目の「ノードn個、エッジm本」という部分の受け取りを行います。
競プロのPythonでの入力受け取りについては、
(https://qiita.com/ell/items/1f519aff0cdc3cf16284)が参考になります。
2. グラフ作成
graph = [[] for _ in range(n+1)] # 2. グラフ作成リスト内包表記を用いて二次元配列graphを作成します。n+1個の[](空リスト)が作られます。
リスト内包表記の基本と活用については、
こちら(https://qiita.com/KTakahiro1729/items/c9cb757473de50652374)が参考になります。
後でこの空リストにappendします(ただしgraph[0]は使わないので、最後まで空リストのまま)。
二次元配列を作るときの記法は上記のようにしましょう。
以下のように書いてしまうと後でgraph.appendをするときに変な挙動をします。
参考:https://sonickun.hatenablog.com/entry/2014/06/13/132821
graph = [[]] * (n+1) # ダメな例3. エッジの受け取り・グラフへの反映
for i in range(m): # 3. エッジの受け取り・グラフへの反映
a, b = map(int, input().split())
graph[a].append(b)
graph[b].append(a)入力の2行目以降の、「エッジがどのノードとどのノードをつなげているか」という部分の受け取りを行います。
ここでは、「graph[i]にはノードiと直接つながっている(*1)ノード番号を入れる」ことを実現したいです。
(*1)「ノードiとノードjが直接つながっている」とは、ここではiとjを結ぶエッジが存在することだとします。
具体的に言うと、2行目以降の入力が
1 3
1 4
2 4だった場合、ノード1と直接つながっているのはノード3と4なので、ノード1については
graph[1] = [3, 4]にしたい、ということです。
ここで、graph[1].append(3)とするとgraph[1]に3(ノード3)がappendされる(*2)ので、「ノード1とノード3が直接つながっている」ことが表現できます。
(*2)
graph[1].append(3)の挙動は以下のようになります。
graph = [[], [], [], [], []]
graph[1].append(3)
print(graph) #[[], [3], [], [], []]
print(graph[1]) #[3]つまりgraph[1]に関してはgraph[1].append(3)とgraph[1].append(4)をしたいのですが、これは
1 3
1 4の入力に対してgraph[a].append(b)をすることで実現できます。
同様にノード3についても、「ノード3にノード1が直接つながっている」ことを表すためにgraph[3].append(1)をする必要があります。入力"1 3"に対してのgraph[3].append(1)なので、graph[b].append(a)とすれば実現できますね。
これが3, 4行目の
graph[a].append(b)
graph[b].append(a)の意味です。
4. 最短距離リストの作成
dist = [-1] * (n+1) # 4. 最短距離リストの作成
dist[0] = 0
dist[1] = 0最短距離を格納するリストを作成します。
dist[i]にはノード1からノード i の最短距離(shortest distance)を入れたいため、要素数が(n+1)のリストを作成しています。
dist[0]には特に意味はありません(一応0という値を入れてありますが、最後には出力しません)。
dist[1]はノード1からノード1の距離なので0と定義しておきます。この定義は後々使うので重要です。
5. 訪問ノードを格納するキュー(deque)の作成
d = deque() # 5. 訪問ノードを格納するキュー(deque)の作成
d.append(1)訪問ノードを格納するキューを作成します。
dequeを使わないで単純にリストを用いても同じことが可能なのですが、今回dに対しては「先頭から要素を取り出す」「末尾に要素を追加する」操作しか行わないので、先頭や最後の要素に対するアクセスが高速に(O(1)で)行えるdequeを使いました(リストだとO(n)になります)。
この問題ではノード1からの最短距離を求めたいので、最初にノード1を訪問してそこから他のノードに向けて出発すると考えることができます。
dequeの使い方はリストに似ており、2行目のd.append(1)は「dの末尾に1を追加する」の意です。
dには後ほど「新しく訪問したノードを末尾に追加する」もしくは「先頭から過去に訪問したノードを取り出す」という操作を繰り返すのですが、ここでd.append(1)を行うのは「ノード1を訪問した」という意味を持つわけです。
ここで覚えておきたいのが、dには上のような操作を繰り返すので、「ノード j がdの要素(dに入っている)」ならば「ノード j には既に訪問済である」ということです。
6. 幅優先探索
while d: # 6. 幅優先探索
v = d.popleft()
for i in graph[v]:
if dist[i] != -1:
continue
dist[i] = dist[v] + 1
d.append(i)今回の実装の要となる部分です。今まで定義してきたgraph, dist, dを用いて幅優先探索を実装していきます。
以下に書いた説明だけでは難しい方もいると思いますので、
こちら(https://qiita.com/drken/items/996d80bcae64649a6580)も参考にしてみると理解が深まります。
(以下の説明は上記の記事で詳しく解説されている概念的な部分には触れずアルゴリズム的な話に終始しているので、上記の記事→以下の説明、の順に読むことをおすすめします)
1行目のwhile文は「dがtrueの間は処理を続ける」、すなわち「dに1つ以上要素が入っているときに処理を続ける」ということです。5. より、dに1つも要素が入っていないというのは「過去に訪問したノードを全て取り出した」、つまり全てのノードに対して探索が終わっている状態を表すので、このwhile文が終わるとき探索も完了します。
2行目のpopleft()はリストでいうpop(0)にあたり、「最左端の要素を削除してその要素を取得する」メソッドです。vはdに入っていた要素なので、既に訪問済のノードのうちの一つであるとわかります。
3~7行目に関しては以下のコメントアウトを参考にしてください。
while d:
v = d.popleft()
for i in graph[v]: # ノードvと直接つながっているノードiに対して
if dist[i] != -1: # 訪問済であれば
continue # スルーして次のiについて調べる
dist[i] = dist[v] + 1 # 未訪問であれば左のように計算してdist[i]を決める
d.append(i) # 今回新しく訪問したノードiをdの末尾に追加3行目のfor i in graph[v]についての詳しいことは、
こちら(https://it-ojisan.tokyo/python-list-for/)が参考になります。
4行目は、distの初期化(4. )でdist[0]とdist[1]以外は-1と定義したので、「dist[i] == 1であれば未訪問(このwhile文の中でまだノード i について調べていない)」ということです。逆にdist[i] != 1なら訪問済であることを表します。
5行目のcontinue文は「この i は訪問済のノードなので次の i を探す」という意味です。
continue文についての詳しいことは、こちら(https://uxmilk.jp/12220)が参考になります。
6行目がこの実装全体の根幹部分です。既に訪問済であるノード v に対して、6行目まで到達したということは(= 5行目のcontinueで次のiに行かなかったということは)ノード i はまだ訪問していないノードということになります。iはgraph[v]の要素なので「ノード v とノード i は直接つながっている」ことがわかりますが、iにはまだ訪問していません。
これは「ノード1からノード v までの最短距離よりノード1からノード i までの最短距離の方が長い」ということを意味します。
これが実際にどのくらい長いかは現時点では不明なのですが、求めたいのは最短距離なので、まずは「ノード1からノード v までの最短距離(dist[v])よりノード1からノード i までの距離の方が1だけ長い」ようなルートがあれば、それは確実に「ノード1からノードiまでの最短距離(dist[i])」となりますよね。
実際、今 v と i は直接つながっているので、「ノード1からノード v まで最短で行って、その次にノード v とノード i をつなぐエッジを通る」ことが実現できて、これがノードiに到達する最短のルートになります。そして上の文から分かる通り、
dist[i] = dist[v] + 1とdist[i]を定義することができます。
たとえば、4. でdist[1]を0と定義しましたが、ノード1とノード2が直接つながっているとしましょう。すると
dist[2] = dist[1] + 1 # dist[1] = 0 なので dist[2] = 1とわかります。ノード2はノード1と直接つながっているのでdist[2] = 1は当たり前と思われるかもしれませんが、これはdist[1] = 0と最初に定義したことから導けた結論です。なにはともあれ、直観と合う結果が出たのではないでしょうか。
7行目は、今distが定義できたiをdの末尾に追加することで、次はノードiと直接つながっている(かつ未訪問の)ノードを調べるのに使います。
7. 最短距離の出力
ans = dist[1:] #7. 最短距離の出力
print(*ans, sep="\n")出力の部分です。dist[0]は出力には不要なのでスライスで消してansという新しいリストにしています。最後の行ではリストのアンパックをしているのですが、要するにやっていることは以下と同じです。
for i in range(len(ans)):
print(ans[i])スライスについて参考となる記事はこちら(https://www.javadrive.jp/python/list/index3.html#google_vignette)
アンパックについて参考となる記事はこちら
(https://note.nkmk.me/python-tuple-list-unpack/)
おわりに
これで無事Pythonでの幅優先探索を実装することができました🎉
効率的に計算できるアルゴリズムと聞くと実装がとても難しいようなイメージがありますが、20行程度のコードで複雑な探索が行えるのは興味深いですね。
「初めての競プロサークル」では、このようにアルゴリズムやその実装方法を学ぶことで、実案件での実装時の処理速度向上を目指しています。
NRIデジタルでは他にもさまざまな有志活動が活発に行われています。
興味を持たれた方は今後のnoteでの紹介も楽しみにしていてください。